
Ce travail s’intègre dans le cadre de la réalisation future de l’interface homme machine d’une borne interactive du musée Confluences. Face à celle-ci, l’utilisateur, filmé par une Webcam masquée, pourra interagir avec le système en utilisant uniquement les mouvements de sa main. Afin de simplifier et de nous concentrer sur la problématique de suivi de la main, nous avons choisi d’utiliser une application existante (Google Earth) et de simuler des évènements (clavier ou souris) qui permettent la navigation au sein de cette application. Ces évènements sont générés en fonction du mouvement de la main de l’utilisateur. Afin de suivre ce déplacement, nous avons décidé d’utiliser une méthode colorimétrique, car elle semblait assez triviale à implémenter à première vue. Cependant, de nombreuses améliorations ont du être apportée afin de rendre le système plus performant. Ce projet a été réalisé en C/C++ à l’aide d’OpenCv, la librairie de traitement d’images d’Intel.
Détection de la couleur de peau
Cette première étape à pour but d’isoler dans l’image les couleurs appartenant à la main. Certaines études ont montré que les couleurs de peau entre plusieurs individus diffèrent très majoritairement dans l’intensité, alors que la chrominance (qui correspond à la teinte et la saturation) reste à peut prêt identique. Afin de se servir de cette propriété, il faut travailler dans un espace qui sépare l’intensité de la chrominance. On a choisi d’utiliser le mode YcrCb qui est bien adapté à la détection de la peau.
– Etude colorimétrique de la main
En capturant une image à partir de la Webcam, on isole la main, puis on place les valeurs de chaque pixel de l’image dans un repère d’axes Cr, Cb. On obtient le graphique suivant :
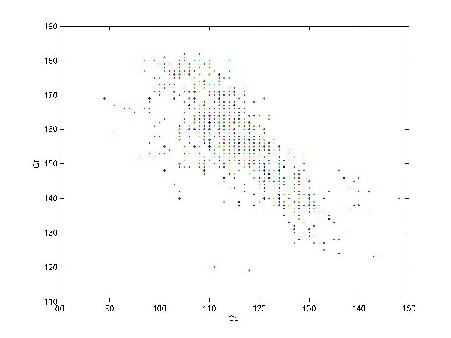
– Récupération des pixels correspondant à la palette de couleur de la main
Sur ce graphique, on remarque que la distribution des valeurs s’apparente à une ellipse. On seuil chaque image à traiter et on obtient une représentation binaire de la scène. Les pixels dont les caractéristiques colorimétriques sont incluses dans l’ellipse apparaissent en blanc, et le reste en noir.

– Opérations morphologiques
Comme l’image binaire doit être soumise à une détection de contours, on la traite d’abord avec un enchaînement d’opérations morphologiques. La fermeture (dilatation puis érosion) suivie de l’ouverture (érosion puis dilatation) permettent d’homogénéiser l’image et de réduire ainsi le nombre de contours détectés (en savoir plus sur les opérateurs morphologiques…).

– Détection des contours
Cette image est ensuite soumise à la fonction de détection de contours d’OpenCv (cvFindContours), qui sans surprise, trouve plusieurs zones. Celles ci correspondent généralement à la tête, aux mains (si les deux sont dans le champ de la caméra) ou/et aux bras (les bras sont détectés si l’utilisateur porte des manches courtes). L’information colorimétrique ne peut pas nous aider à établir la distinction entre la main et les autres zones détectées. Il faut la combiner avec une méthode qui se base sur un autre principe.
Utilisation d’une information de mouvement
D’une manière générale, il faut trouver des caractéristiques qui permettent de séparer la tête de la main. Nous aurions pu nous baser par exemple sur la forme du contour de la main. Même, si des méthodes permettent de reconnaître efficacement une forme dans une image, quelle que soit sa taille, cette solution nous paraissait peu propice à notre situation. En effet, dans le cas ou l’utilisateur porte des manches courtes, le bras et la main font parti la même zone détectée. Ainsi, la forme elle-même du contour, et non pas juste son échelle, pose problème.
L’autre solution consiste à faire l’hypothèse que contrairement à la main, la tête reste en grande partie immobile. L’idée alors, est d’éliminer les zones qui ne bougent pas, dans l’image soumise à la détection de contour. Dans un premier temps, on construit une image couleur qui « mémorise » les mouvements (nommons la « image_mem(t) »), en superposant une fraction (alpha) de l’image capturée par la Webcam avec l’image précédemment établie (« image_mem(t-1) »). Sur l’image ainsi crée, les mouvements laissent des traces qui disparaissent plus ou moins vite en fonction du paramètre alpha.

En soustrayant cette image (« image_mem(t) ») avec l’image initiale, et en seuillant le résultat, on garde uniquement les zones en mouvement.

Maintenant que l’on possède une information de mouvement, il faut la corréler avec la détection de couleur précédemment établie. En établissant un ET logique entre l’image d et f, on ne détecte que les zones en mouvement qui ont une couleur proche de celle de la peau (image g).

Si la tête reste a peu prêt immobile, elle n’interfère pas dans la détection de la main. Les contours ayant une aire trop petite pour pouvoir correspondre à la main sont ignorés.
De cette manière, le suivi de la main fonctionne plutôt bien. Sur l’image h, le cercle vert entoure le point le plus haut du contour considéré par le système comme une main. Les deux autres cercles correspondent aux autres contours détectés, qui font la plupart du temps partie du bras. C’est pourquoi le contour choisi est celui qui ce situe le plus haut dans l’image.

La main est bien détectée mais sa position tremble. Ceci est gênant lors du contrôle du mouvement de la souris. Pour y remédier, on garde en mémoire les N dernières positions de la main et on les moyenne afin d’obtenir les nouvelles coordonnées. Cela permet d’obtenir un mouvement plus fluide et sans à-coups.
Contrôle des évènements de la souris
Dans un premier essai d’interface, nous pensions interagir avec Google Earth en simulant le mouvement de la souris, le double clic gauche (zoom et recentre sur le point voulu) et le double clic droit (s’éloigner et recentre sur le point voulu). De cette façon, ces trois événements permettent de naviguer sur tout le globe terrestre.
– Mouvement de la souris
Le déplacement du curseur de la souris est établi relativement au déplacement de la main. On compare d’abord la position actuelle de la main avec l’une des positions précédentes (qui ont été mémorisées), ce qui donne son déplacement en X et en Y. On ajoute ensuite aux coordonnées actuelles du curseur de la souris, les différences calculées précédemment (à un coefficient près qui permet de réguler la vitesse de la souris). Avec cette méthode, le mouvement de la souris à l’écran est agréable et assez précis.
– Simuler un clic
Si déplacer le curseur n’a pas trop posé de problème, simuler un clic s’est avéré plus dur que ce que nous imaginions. Parmi les actions réalisables par la main (écarter les doigts, fermer le poing, tourner la main), il a fallu déterminer lesquelles pouvaient être détectées par le système. Lorsque l’on ferme le poing et qu’on le rouvre, le point le plus haut du contour descend avant de revenir à sa position initiale. Par expérience, on trouve que la durée de ce mouvement reste à peu près constante (si la fermeture et l’ouverture du poing se font toujours à la même vitesse).On considère alors qu’il y a une volonté de clic si la durée d’un mouvement est proche de la valeur précédemment déterminée.
Tous les mouvements dont la durée correspond à la durée de fermeture/ouverture du poing sont désormais considérés comme un clic. Cela constitue le défaut majeur de cette technique. Afin de limiter les clics intempestifs, une condition est rajoutée en plus de la durée. Le point d’arrivée du mouvement doit être proche de son point de départ (ce qui est bien évidemment le cas lors de la fermeture/ouverture du poing).
Ainsi, lorsque l’utilisateur ferme puis ouvre sa main, le système exécute l’événement de souris « double clic gauche ». Comme il était difficile d’imaginer une autre action détectable, l’événement « double clic droit » est envoyé lorsque deux intentions de clic sont détectées pendant un cours instant.
Malheureusement, ce système de clic s’est avéré assez décevant. Des clics sont souvent générés à l’insu de l’utilisateur et il n’est pas toujours facile de les déclencher, surtout pour une personne qui n’a aucune idée du fonctionnement du système. On comprend mieux pourquoi certaines applications commerciales du même type font le choix de déclencher un clic lorsque l’on maintient une position pendant un certain temps. Dans ce cas, il suffit juste de détecter l’arrêt de la main, ce qui rend la tâche beaucoup moins complexe.
Afin de réaliser une interface plus fonctionnelle, nous avons ensuite opté pour une navigation qui ne nécessite pas de clic.
Evénement claviers
Il est possible de naviguer dans Google Earth grâce à des raccourcis clavier. On se propose de générer 4 différentes actions (zoomer, s’éloigner, faire pivoter la terre vers la gauche et vers la droite). L’image est divisée en 5 zones comme suit :

Différents événements se produisent en fonction de la position de la main dans l’image.
La partie centrale est une zone neutre, dans laquelle rien ne se passe. Cela permet a l’utilisateur de stopper tout mouvement. Le zoom est effectué dans les parties hautes et basses tandis que la rotation de la terre se fait dans les zones latérales.
Cette interface très simple rend la navigation dans Google Earth agréable, même si tout le globe n’est pas explorable dans sa globalité avec ces 4 actions. Bien sur, il serait possible de diviser l’image en plus de zones afin de pouvoir générer les évènements manquants. La navigation demanderait alors un peu plus d’entraînement.
Conclusions et améliorations
Dans cet exemple, l’initialisation des propriétés colorimétrique de la main est faite manuellement. Pour une application réelle, il serait nécessaire d’effectuer ce calibrage dès que les paramètres de luminosité changent car le système reste sensible à ces variations. Si celles-ci sont brutales, l’initialisation peut difficilement être faite sans action de l’utilisateur. Cependant, si les propriétés de l’éclairage varient lentement, on peut imaginer que le système puisse s’y adapter, en effectuant un calibrage basé sur la position actuelle de la main.
D’une manière générale, il est évident que la méthode colorimétrique seule n’est pas suffisante pour réaliser le suivi de la main. D’autres procédés ont du y être ajoutés afin d’obtenir un résultat correct.
Sources :
– Site officiel d’OpenCv :http://www.intel.com/technology/computing/opencv/index.htm
– Liste des fonctions de la librairie OpenCv :
http://www.cs.bham.ac.uk/resources/courses/robotics/doc/opencvdocs/ref
– Projet robota : Projet utilisant une méthode colorimétrique similaire. http://robota.epfl.ch/